

Détails techniques : Formation BSGAL, architecture Swin-L et stratégie de seuil dynamique
Table des liens
Abstrait et 1 Introduction
-
Travaux connexes
2.1. Augmentation de données générative
2.2. Apprentissage actif et analyse de données
-
Préliminaire
-
Notre méthode
4.1. Estimation de la contribution dans le scénario idéal
4.2. Apprentissage actif génératif par lots en streaming
-
Expériences et 5.1. Paramètre hors ligne
5.2. Paramètre en ligne
-
Conclusion, Impact plus large et Références
\
A. Détails d'implémentation
B. Plus d'ablations
C. Discussion
D. Visualisation
A. Détails d'implémentation
A.1. Ensemble de données
Nous avons choisi LVIS (Gupta et al., 2019) comme ensemble de données pour nos expériences. LVIS est un ensemble de données de segmentation d'instances à grande échelle, comprenant environ 160 000 images avec plus de 2 millions d'annotations de segmentation d'instances de haute qualité réparties sur 1203 catégories du monde réel. L'ensemble de données est en outre divisé en trois catégories : rare, commune et fréquente, en fonction de leur occurrence dans les images. Les instances marquées comme "rares" apparaissent dans 1 à 10 images, les instances "communes" apparaissent dans 11 à 100 images, tandis que les instances "fréquentes" apparaissent dans plus de 100 images. L'ensemble de données global présente une distribution à longue traîne, ressemblant étroitement à la distribution des données dans le monde réel, et est largement appliqué dans de multiples contextes, y compris la segmentation à quelques exemples (Liu et al., 2023) et la segmentation en monde ouvert (Wang et al., 2022; Zhu et al., 2023). Par conséquent, nous pensons que la sélection de LVIS permet de mieux refléter les performances du modèle dans des scénarios du monde réel. Nous utilisons les divisions officielles de l'ensemble de données LVIS, avec environ 100 000 images dans l'ensemble d'entraînement et 20 000 images dans l'ensemble de validation.
A.2. Génération de données
Notre processus de génération et d'annotation de données est cohérent avec Zhao et al. (2023), et nous le présentons brièvement ici. Nous utilisons d'abord StableDiffusion V1.5 (Rombach et al., 2022a) (SD) comme modèle génératif. Pour les 1203 catégories de LVIS (Gupta et al., 2019), nous générons 1000 images par catégorie, avec une résolution d'image de 512 × 512. Le modèle de prompt pour la génération est "a photo of a single {CATEGORY NAME}". Nous utilisons respectivement U2Net (Qin et al., 2020), SelfReformer (Yun and Lin, 2022), UFO (Su et al., 2023) et CLIPseg (Luddecke and Ecker, 2022) pour annoter les images génératives brutes, et sélectionnons le masque avec le score CLIP le plus élevé comme annotation finale. Pour garantir la qualité des données, les images avec des scores CLIP inférieurs à 0,21 sont filtrées comme des images de faible qualité. Pendant l'entraînement, nous employons également la stratégie de collage d'instances fournie par Zhao et al. (2023) pour l'augmentation des données. Pour chaque instance, nous la redimensionnons aléatoirement pour correspondre à la distribution de sa catégorie dans l'ensemble d'entraînement. Le nombre maximum d'instances collées par image est fixé à 20.
\ De plus, pour élargir davantage la diversité des données générées et rendre notre recherche plus universelle, nous utilisons également d'autres modèles génératifs, notamment DeepFloyd-IF (Shonenkov et al., 2023) (IF) et Perfusion (Tewel et al., 2023) (PER), avec 500 images par catégorie par modèle. Pour IF, nous utilisons le modèle pré-entraîné fourni par l'auteur, et les images générées sont la sortie de l'étape II, avec une résolution de 256×256. Pour PER, le modèle de base que nous utilisons est StableDiffusion V1.5. Pour chaque catégorie, nous affinons le modèle en utilisant les images recadrées de l'ensemble d'entraînement, avec 400 étapes d'affinage. Nous utilisons le modèle affiné pour générer des images.
\ 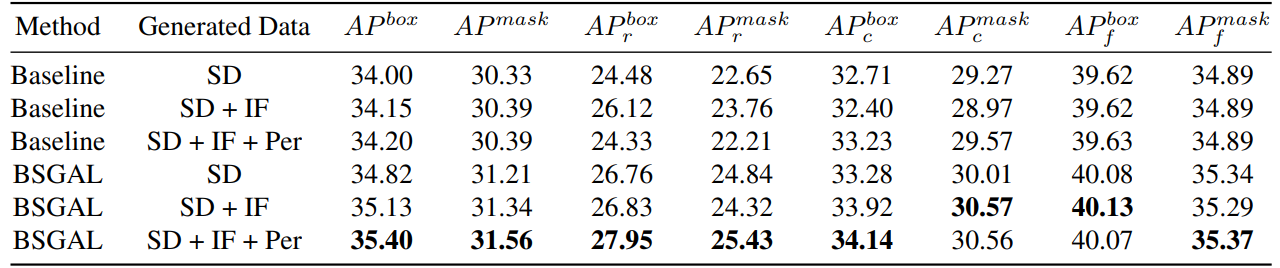
\ Nous explorons également l'effet de l'utilisation de différentes données générées sur les performances du modèle (voir Tableau 7). Nous pouvons voir que sur la base du StableDiffusion V1.5 original, l'utilisation d'autres modèles génératifs peut apporter une certaine amélioration des performances, mais cette amélioration n'est pas évidente. Plus précisément, pour des catégories de fréquence spécifiques, nous avons constaté que IF présente une amélioration plus significative pour les catégories rares, tandis que PER présente une amélioration plus significative pour les catégories communes. Cela est probablement dû au fait que les données IF sont plus diverses, tandis que les données PER sont plus cohérentes avec la distribution de l'ensemble d'entraînement. Considérant que les performances globales ont été améliorées dans une certaine mesure, nous adoptons finalement les données générées de SD + IF + PER pour les expériences ultérieures.
A.3. Entraînement du modèle
Suivant Zhao et al. (2023), nous utilisons CenterNet2 (Zhou et al., 2021) comme notre modèle de segmentation, avec ResNet-50 (He et al., 2016) ou Swin-L (Liu et al., 2022) comme backbone. Pour ResNet-50, l'itération maximale d'entraînement est fixée à 90 000 et le modèle est initialisé avec des poids d'abord pré-entraînés sur ImageNet-22k puis affinés sur LVIS (Gupta et al., 2019), comme Zhao
\ 
\ et al. (2023) l'ont fait. Et nous utilisons 4 GPU Nvidia 4090 avec une taille de lot de 16 pendant l'entraînement. Quant à Swin-L, l'itération maximale d'entraînement est fixée à 180 000 et le modèle est initialisé avec des poids pré-entraînés sur ImageNet-22k, car nos premières expériences montrent que cette initialisation peut apporter une légère amélioration par rapport aux poids entraînés avec LVIS. Et nous utilisons 4 GPU Nvidia A100 avec une taille de lot de 16 pour l'entraînement. De plus, en raison du grand nombre de paramètres de Swin-L, la mémoire supplémentaire occupée par la sauvegarde du gradient est importante, nous utilisons donc en réalité l'algorithme de l'Algorithme 2.
\ Les autres paramètres non spécifiés suivent également les mêmes paramètres que X-Paste (Zhao et al., 2023), tels que l'optimiseur AdamW (Loshchilov and Hutter, 2017) avec un taux d'apprentissage initial de 1e−4.
A.4. Quantité de données
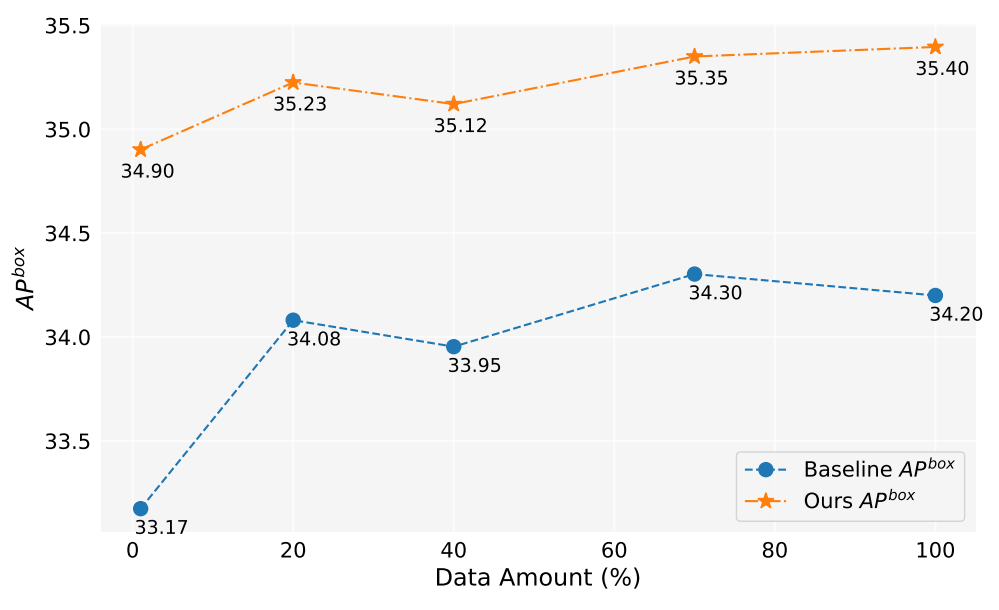
Dans ce travail, nous avons généré plus de 2 millions d'images. La Figure 5 montre les performances du modèle lors de l'utilisation de différentes quantités de données générées (1%, 10%, 40%, 70%, 100%). Dans l'ensemble, à mesure que la quantité de données générées augmente, les performances du modèle s'améliorent également, mais il y a aussi une certaine fluctuation. Notre méthode est toujours meilleure que la référence, ce qui prouve l'efficacité et la robustesse de notre méthode.
A.5. Estimation de la contribution
\ Ainsi, nous calculons essentiellement la similarité cosinus. Ensuite, nous avons effectué une comparaison expérimentale, comme le montre le Tableau 8,
\ 
\ 
\ nous pouvons voir que si nous normalisons le gradient, notre méthode aura une certaine amélioration. De plus, comme nous devons maintenir deux seuils différents, il est difficile d'assurer la cohérence du taux d'acceptation. Nous adoptons donc une stratégie de seuil dynamique, préréglons un taux d'acceptation, maintenons une file d'attente pour sauvegarder la contribution de l'itération précédente, puis ajustons dynamiquement le seuil en fonction de la file d'attente, de sorte que le taux d'acceptation reste au taux d'acceptation préréglé.
A.6. Expérience jouet
Voici les paramètres expérimentaux spécifiques mis en œuvre sur CIFAR-10 : Nous avons utilisé un simple ResNet18 comme modèle de référence et avons effectué un entraînement sur 200 époques, et la précision après l'entraînement sur l'ensemble d'entraînement original est de 93,02%. Le taux d'apprentissage est fixé à 0,1, utilisant l'optimiseur SGD. Un momentum de 0,9 est en vigueur, avec une décroissance de poids de 5e-4. Nous utilisons un planificateur de taux d'apprentissage à recuit cosinus. Les images bruitées construites sont représentées sur la Figure 6. Une baisse de la qualité de l'image est observée à mesure que le niveau de bruit augmente. Notamment, lorsque le niveau de bruit atteint 200, les images deviennent significativement difficiles à identifier. Pour le Tableau 1, nous utilisons Split1 comme R, tandis que G se compose de 'Split2 + Noise40', 'Split3 + Noise100', 'Split4 + Noise200',
A.7. Une simplification Forward une seule fois
\
:::info Auteurs :
(1) Muzhi Zhu, avec une contribution égale de l'Université de Zhejiang, Chine ;
(2) Chengxiang Fan, avec une contribution égale de l'Université de Zhejiang, Chine ;
(3) Hao Chen, Université de Zhejiang, Chine (haochen.cad@zju.edu.cn) ;
(4) Yang Liu, Université de Zhejiang, Chine ;
(5) Weian Mao, Université de Zhejiang, Chine et Université d'Adélaïde, Australie ;
(6) Xiaogang Xu, Université de Zhejiang, Chine ;
(7) Chunhua Shen, Université de Zhejiang, Chine (chunhuashen@zju.edu.cn).
:::
:::info Cet article est disponible sur arxiv sous la licence CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
\
Vous aimerez peut-être aussi

Le PDG de JPMorgan avertit qu'une Europe faible menace la stabilité économique des États-Unis

Héros éprouvé : Jacob Cortez apporte son talent décisif de San Beda à la quête du titre de La Salle
