

从「东数西算」到「六大网络」:一场静悄悄的算力会战
文章作者、来源:0x9999in1,ME News
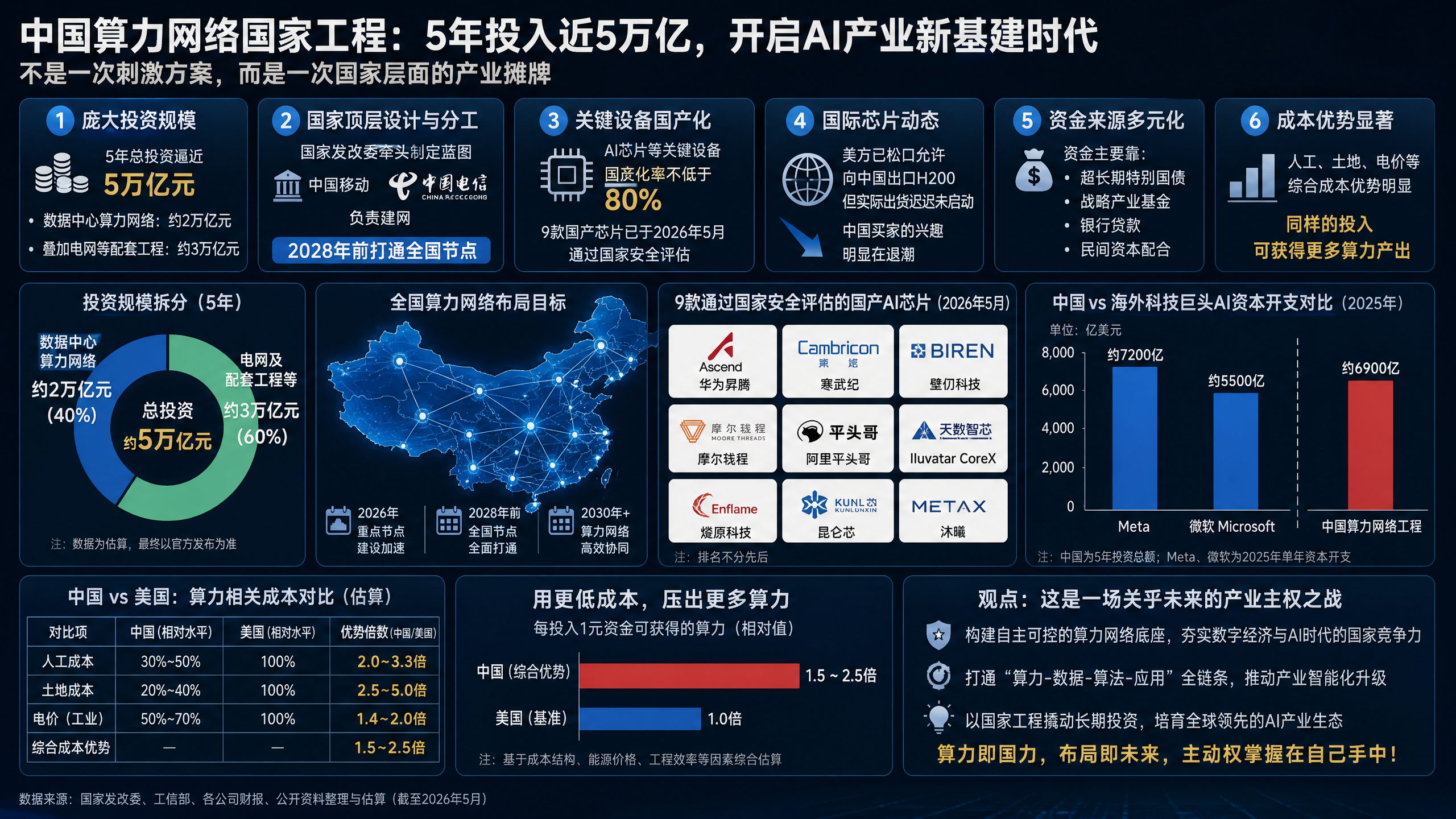
TL;DR
- 中国计划用五年时间投入约2万亿元人民币,搭建一张全国互联的数据中心算力网络,叠加电网等配套工程,总投资规模逼近5万亿元
- 国家发改委牵头制定蓝图,中国移动、中国电信负责建网,2028年前打通全国节点
- AI芯片等关键设备国产化率被锁定为不低于80%,华为系、寒武纪、壁仞、摩尔线程、阿里平头哥等9款国产芯片已在2026年5月通过国家安全评估
- 美方已松口允许向中国出口H200,但实际出货迟迟未启动,中国买家的兴趣明显在退潮
- 资金主要靠超长期特别国债和战略产业基金,银行贷款和民间资本配合
- 总盘子仍低于Meta、微软今年单年的AI资本开支(约7250亿美元),但人工、土地、电价的成本优势会把每一块钱压出更多算力
- 这不是一次刺激方案,这是一次国家层面的产业摊牌
这一次不是花钱,是站队
2万亿元。
五年。
折成美元,2950亿。
数字甩出来,很多人第一反应是:不算多。
毕竟Meta和微软今年一年在AI上的资本开支,加起来就是7250亿美元。换算下来,人家一年砸的,顶中国五年规划的两倍多。
那为什么这则消息一出来,英伟达的股价当天还是被砸出一根长长的阴线?
因为这次的关键不在2万亿,而在那个被很多人忽略掉的数字——80%。
国家发改委牵头的算力网络蓝图,据知情人士披露,拟规定数据中心采购的AI芯片等关键设备中,本土供应商的占比不得低于80%。这意味着剩下20%的窗口,是英伟达、AMD、还是别的什么海外玩家,要去抢的盘子。
20%是什么概念?
中国移动、中国电信此前公开的智算采购大单,英伟达份额一度接近85%。一边是85,一边是20,中间这65个百分点,就是这次摊牌的真实分量。
这不是一次简单的财政刺激。
这是一次明牌的产业站队。
钱从哪来,谁来花,花在哪
先把钱的事讲清楚。
这次2万亿的资金来源,不是地方债,也不是常规预算盘子。主渠道是10年期以上的超长期特别国债,加上战略产业国家投资基金。银行贷款和民间资本作为补充。
这个组合很有意思。
超长期特别国债意味着什么?意味着这是一笔不指望短期回本的钱。锁死期限,锁死用途,锁死方向。哪怕中间宏观环境再波动,这笔钱不会被挪去填别的窟窿。
国家投资基金又意味着什么?意味着政府不只是出钱,还要出股权。投出去的每一笔,既是补贴,也是资产。
钱怎么花?
主体不是地方政府,不是民营互联网公司,而是中国移动、中国电信这两家国有运营商。它们承担数据中心的建设、运营和互联,目标是在2028年前把全国分散的算力节点连成一张网。
这个安排其实早有伏笔。
2022年正式启动的「东数西算」工程,已经把内蒙古、贵州、宁夏、甘肃、京津冀、长三角、粤港澳、成渝这八大节点框架搭好了。但「东数西算」更多是规划性、引导性的政策,真正的资金主力还在地方和企业。
这一次,中央财政顶上来了。
地方招商、企业自建、运营商承包,这条线被收编进了一张清晰的国家级蓝图里。
算力网络建设被列入「六大网络」国家战略,和水利、电力、交通这些老牌基础设施摆在一起。这个定位本身就说明了一切——算力,在2026年的中国,被官方重新定义为基础设施。
不是产业,是基础设施。
这两个词的差别,很大。
80%红线背后,是一场提前打完的仗
回到那条80%红线。
为什么是80%而不是50%、不是100%?
100%意味着完全闭门造车,中国还做不到。某些高端环节,比如最先进制程的代工、HBM存储、CoWoS先进封装,本土能力仍在追赶,百分之百国产化的供应链不现实。
50%意味着没诚意。给海外厂商留太大空间,前几年的供应链阵痛就白受了。
80%是一个精算过的数字。
它既给国产留出了规模化放量的窗口,又给最关键、最难替代的几个零部件留了一条缝。
这条红线能划出来,前提是国产替代真的扛得住。
2026年5月,国家科技安全机构通过了9款国产AI芯片的安全评估。名单里有华为昇腾系列、阿里平头哥、壁仞科技、摩尔线程,还有寒武纪等几家头部玩家。
通过安全评估意味着什么?
意味着这些芯片可以名正言顺地进入金融、医疗、制造、物流这些对数据敏感、对自主可控有硬性要求的行业。这一关过了,后面就是订单的问题,不再是资格的问题。
华为昇腾这两年的产能爬坡,业内有目共睹。910B、910C陆续交付,虽然单卡性能仍逊于英伟达H100、H200,但通过CloudMatrix这类整柜整集群的系统级方案,实际跑大模型训练的总吞吐已经能打。
阿里平头哥的含光、倚天系列,主攻自家云上的推理场景。
壁仞、摩尔线程虽然规模小,但在国产生态里补位很明显。
寒武纪重新被资本市场认可,股价一年翻了几倍。
把这些拼起来看,国产AI算力芯片不是「能用」的问题,是「能不能扛主力」的问题。
蓝图里那条80%,本质上是政府帮国产芯片把市场需求侧锁死了。
需求锁死,产能就敢扩,生态就敢投,人才就敢压。
这是一套闭环。
H200出不了货,英伟达在中国的黄金时代真的过了
英伟达这边,故事也走到了一个分水岭。
美方今年早些时候松口,同意向中国买家出售上一代H200。听起来像是一次缓和。
但实际呢?
实际是中方买家的下单热情远低于预期。H200的实际出货,到现在还没真正铺开。
为什么?
因为时机错了。
H200是英伟达2023年推出的产品,算力指标在当时确实领先。但放到2026年,它已经是一个上一代的方案。同期英伟达的旗舰是Blackwell架构的B200、GB200,以及刚刚迭代的Rubin系列。
中国买家要的是顶配,得不到。退而求其次买H200,等于花真金白银采购一代落后的产品,还要承担未来政策反复的风险。
更关键的是,信心结构变了。
过去几年,中国云厂商、互联网大厂一边喊国产,一边偷偷囤英伟达。这种两面下注的策略很务实,也很坦诚——没人想把自己的训练任务押在还没成熟的国产卡上。
但2026年的情况,真的不一样了。
DeepSeek、阿里通义、字节豆包、月之暗面,这些一线大模型团队,公开材料里的国产芯片使用比例都在快速爬升。一些训练任务已经在昇腾集群上跑完了完整的预训练流程。
当头部团队用国产卡跑出了像样的成绩,中尾部团队的心理障碍就被打掉了。
这是一种典型的「示范效应」。
英伟达原本最大的护城河,不只是CUDA,也不只是性能,而是「不敢不用」的心理共识。
这种共识一旦松动,后面就是雪崩。
H200出不了货,本质不是政策问题,是市场问题。
算力不是建出来就赢
但这里要泼一盆冷水。
算力网络这件事,不是建出来就算赢。
历史上类似的「举国建网」工程,有成功的,也有失败的。
成功的范本是高铁。从2008年京津城际开通,到现在覆盖全国的4.5万公里高铁网,十几年时间,中国高铁不仅建出了网,还把成本、技术、运营标准都做到了世界级。
失败的反面教材是什么?
是2010年前后那一波光伏、风电的产能扩张。地方政府疯狂上项目,补贴撒得到处都是,结果产能严重过剩,大批企业死掉,留下一地鸡毛。后来产业重整,洗牌之后才走出来。
数据中心这件事,会是哪一种?
要看几个细节。
第一个细节是用电。
数据中心是吞电怪兽。一个10万卡规模的智算中心,峰值功率可以轻松突破150兆瓦。2万亿规划如果真要落地,配套的电网升级和清洁能源供给必须同步上来。这也是为什么蓝图里把电网改造一起算进去,总投资才会冲到5万亿。
国家电网2025年公布的规划里,「西电东送」二期、特高压新增线路、新能源消纳改造,几个大项目都已经在跟「东数西算」节点协同。这部分如果跟不上,西部数据中心就会变成一堆等着停电的钢筋混凝土。
第二个细节是利用率。
中国数据中心机柜的平均上架率,这两年一直是个老大难。工信部数据显示,2024年全国在用数据中心机柜上架率不到60%。也就是说,建好的算力,有四成是空转的。
智算中心的情况会好一些,因为AI需求真实存在,但也要警惕另一种风险——重复建设。每个省都想要自己的智算中心,每个地方政府都想要补贴,最后拼出来的是分散的小集群,而不是真正高效的大网络。
这次国家发改委牵头,运营商主导,一定程度上就是要解决这个「各自为战」的痛点。
但能不能解决,要看执行,不看蓝图。
第三个细节是模型的真实需求。
算力是为模型服务的。如果未来三五年,大模型的scaling law没有继续兑现,如果Agent、具身智能这些应用场景不能真正起量,那么这2万亿的算力,会面临一个很尴尬的问题——建出来,谁用?
这不是危言耸听。OpenAI、Anthropic、Google DeepMind在2025年到2026年的几次内部分歧,核心都围绕一个问题:scaling还有效吗,要不要继续往上堆算力。
中国押的也是这个赌注。
押对了,2万亿是底,后面还会再加。
押错了,2万亿就是一个昂贵的纪念碑。
跟美国比,我们到底在比什么
很多人喜欢拿2万亿和美国巨头的资本开支做对比。
7250亿美元 vs 2950亿美元。
数字差距不小。
但这种对比其实有点误导。
第一,周期不一样。美国巨头说的是单年开支,而且是私营企业根据市场预期自主决定的;中国说的是五年规划,是政府层面的方向性投入。
第二,成本结构不一样。中国的劳动力成本、土地成本、电价、混凝土钢筋这些基础投入,都比美国便宜不少。地方政府的产业补贴、税收优惠、土地划拨,又能进一步压低实际投入。
同样1美元,在贵州、内蒙古建数据中心,能买到的算力底座,比在德州、弗吉尼亚多出多少?
业内一个粗算的口径是,土建+电力+人工的综合成本,中国大约是美国的三分之一到二分之一。这意味着同样一笔钱,中国能折算出的实际机柜数量、机房面积、运维容量,都要乘上一个系数。
但软的地方也得看清楚。
英伟达Blackwell单卡的算力密度、HBM带宽、互联带宽,目前国产卡仍有差距。所谓「同样的钱建更多机柜」,机柜里塞的卡如果性能差三成,总账算下来可能就拉平了。
更现实的对比方式不是看金额,是看产出。
到2028年,中国能用2万亿建出一张什么样的算力网?
是1000 EFLOPS的有效算力,还是2000 EFLOPS?
这一万、两万张训练集群里,跑出来的是世界一流的模型,还是只是国内自循环的工具?
这才是真正要问的问题。
这场仗最微妙的一环,叫生态
硬件可以砸钱,产能可以爬坡,芯片设计可以追赶。
最难的,从来都是生态。
CUDA从2007年发布到现在,快20年。它积累的不是一套软件库,而是一代又一代AI研究者、工程师、博士生的肌肉记忆。
国产芯片的对标方案,华为有CANN,寒武纪有Neuware,平头哥有HanGuang AI Stack。各家都在做,但一个不能回避的现实是——它们之间不互通。
你的代码在昇腾上跑得好好的,挪到寒武纪就要重写。挪到壁仞,又是另一套API。
这个问题不是华为一家能解决的,也不是政府发个文件就能统一的。
需要的是时间、是开源社区、是真正的开发者生态。
好消息是,2025年下半年开始,几家头部国产芯片厂商开始推「统一异构计算框架」,代号有点拗口,叫XPU-X或者类似的名字。基本思路是搞一套类PyTorch后端,屏蔽底层差异,让上层模型代码可以跨芯片运行。
进展有,但还远谈不上成熟。
蓝图里给到2028年,留了不到三年的窗口。
三年时间,生态能不能起来?
老实说,我不乐观,但也不悲观。
中国软件生态这件事,过去十年的故事是被低估了的。微信支付、抖音算法、拼多多供应链、SHEIN的小单快反,这些底层都靠的是中国工程师独特的工程能力。
AI算力软件栈,会不会复制这个故事,要看接下来这几年。
真正改变格局的,从来不是单一变量
写到这里,我想说一个被很多人忽略的视角。
这次的2万亿、80%、五年、六大网络,看起来是一组孤立的政策动作。
但放到更大的图景里看,它和另外几件事是同一条线。
一条是2025年开始的国债扩张周期。30年、50年期超长期特别国债被反复用作政策工具,资金被定向投入科技、能源、交通这些「大基建」领域。
一条是2026年初出炉的「人工智能+」行动方案,从教育、医疗到工业、农业,AI落地场景被国家层面定义为优先方向。
一条是地方层面的算力补贴。北京、上海、深圳、合肥、贵阳,几乎每个一二线城市都有自己的智算补贴政策,部分地方政府甚至直接出钱采购国产卡然后转租给企业用。
这几条线拼起来,你会发现一个清晰的画面——
供给侧建网,需求侧开闸,资金侧续命,生态侧补位。
这不是单点突破,是一次系统性的产业结构调整。
类似的国家级产业级动员,过去30年中国做过几次。家电、造船、面板、新能源车、光伏、动力电池。每一次都被外界质疑过「产能过剩」「重复建设」「补贴依赖」,每一次最后又都在全球市场里站住了脚。
这一次,会不会例外?
不必过度乐观,也不该过度悲观
最后,我想给一个还算克制的判断。
2万亿+80%+五年这套组合拳,大概率会让中国AI产业在2028年前后,形成一张真正可用、可规模化、可自主可控的算力底座。
它不会完全摆脱海外技术依赖,顶级制程、HBM、CoWoS这些关键环节短期还要靠进口或者绕道。
它也不会一夜间击败英伟达,后者在全球AI市场的统治地位,至少到2030年仍然稳固。
但它会做到一件事——让中国大模型团队、AI应用团队、智能制造团队,不再活在「下一轮制裁会不会断货」的焦虑里。
这件事的价值,不能只用GDP、不能只用算力FLOPS、不能只用财务回报来衡量。
它是一种确定性。
这种确定性一旦建立,后面的产业故事会自然展开。
英伟达会继续在中国卖一些卡,但不会再是主角。
华为、寒武纪、壁仞、摩尔线程、平头哥们,会真正长出自己的生态、自己的客户、自己的护城河。
地方政府的算力补贴热,会经历一轮泡沫,然后回归理性。
民营资本会重新涌入AI基础设施,但路径会变——不再是All in英伟达,而是和国产卡、国产框架、国产云深度绑定。
整个故事的底层叙事,会从「追赶」慢慢变成「并行」,再过几年,可能会变成「分叉」。
是不是看得见的赢?
不一定。
但是不是一次必须打的仗?
是。
2万亿,五年,80%。
这三个数字摆在桌上,牌已经亮了。
剩下的,就看打牌的人,有没有真功夫。
参考资料
- 国家发展和改革委员会,《全国一体化大数据中心协同创新体系算力枢纽实施方案》,2021
- 国务院,《"十四五"数字经济发展规划》,2022
- 工业和信息化部,《全国数据中心机架资源与上架率统计报告》,2024
- 国家电网公司,《新型电力系统行动方案(2024—2027)》,2024
- 中国信息通信研究院,《中国算力发展指数白皮书(2025年)》
- Bloomberg,"China Plans \$295 Billion Data Center Network to Boost AI Push",2026
- Financial Times,"China's Push for Domestic AI Chips Reaches New Milestone",2026
- Reuters,"Nvidia H200 Shipments to China Stall as Local Alternatives Gain Ground",2026


您可能也会喜欢

AI 正在制造新的”信息穷人”?

SpaceX Pre IPO期货在加密市场飙升

AgentOn 与 Clustr100 达成战略合作:陆续公布联合任务与生态计划



