

Gemini 3.1 Pro vs Claude Opus 4.6 – сравнение февральских новинок

Две недели. Именно столько понадобилось, чтобы гонка ИИ-гигантов превратилась в полноценную войну миров.
5 февраля Anthropic выпускает Claude Opus 4.6 – короля экспертных задач, который мгновенно захватывает вершины рейтингов качества и пользовательских симпатий. Ажиотаж, восторг, заголовки.
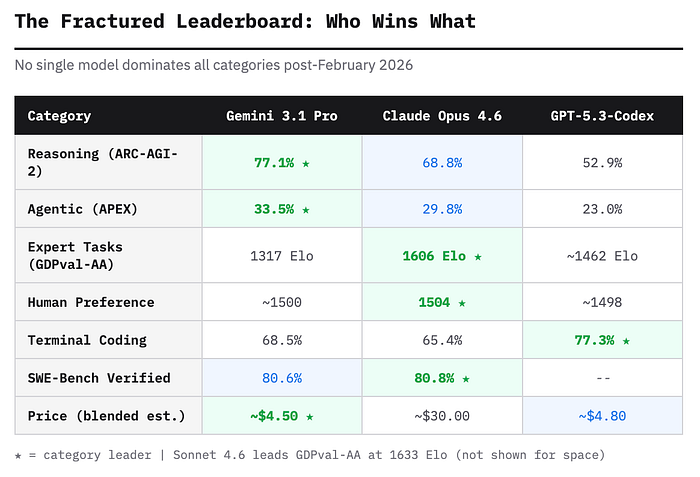
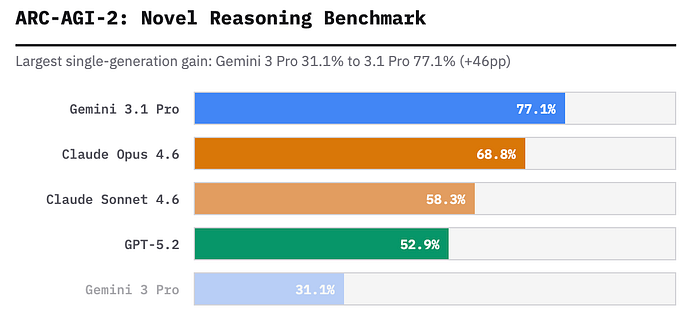
Но 19 февраля Google берёт паузу... и выстреливает Gemini 3.1 Pro. Результат? +46 процентных пунктов в тесте ARC-AGI-2 (77,1% против 31,1% у предшественника), лидерство в 12 из 18 бенчмарков и ценник, от которого у конкурентов округляются глаза.
Gemini 3.1 Pro вдвое обходит предшественника в тестах на рассуждение, стоит в 6,5 раза дешевле флагмана конкурента и штампует 3D-симуляции птичьих стай по текстовому описанию. Claude Opus 4.6, который не гонится за скоростью, а размышляет вслух, взвешивает моральные дилеммы и остаётся любимцем людей в слепых тестах.
Как не запутаться в этом треугольнике и выбрать модель под свои задачи? И почему эксперты в финансах и юриспруденции отдают предпочтение Sonnet 4.6, оставляя “тяжеловесов” далеко позади?
Разобрали 18 бенчмарков, чтобы вы поняли, за какой моделью – ваше завтра. В этом материале мы свели все цифры, графики и пользовательские ощущения, чтобы у вас была полная картина февральской перезагрузки. Узнайте, какая модель сделает вашу работу лучше, быстрее и дешевле и кто победит в этой дуэли – цифровой гений-отличник или философ с душой.
TL;DR
-
Gemini 3.1 Pro (19 февраля) возглавляет более 12 из 18 тестов, показав впечатляющие 77,1% в ARC-AGI-2 (новое рассуждение) при цене 2 $/12 $ за миллион токенов.
-
Claude Opus 4.6 (5 февраля) доминирует в экспертных задачах (GDPval-AA: 1606 Elo), пользовательских предпочтениях (№ 1 в LMArena) и рассуждении с использованием инструментов.
-
Google и Anthropic внедрили регулируемую глубину мышления (3 уровня у Gemini и 4 уровня у Claude), превратив оптимизацию затрат в решение на уровне каждого запроса.
Ускоряйте рутинные задач вместе с BotHub! Для доступа не нужен VPN. По ссылке вы получите 300 000 бесплатных токенов, чтобы перейти к работе с нейросетями прямо сейчас!
Февральская перезагрузка
В гонке передового ИИ три месяца – это почти вечность. Но февраль 2026-го сжал год конкурентной перегруппировки всего в две недели.
5 февраля Anthropic представил Claude Opus 4.6 – модель, мгновенно занявшую первые позиции по качеству экспертных задач, пользовательским предпочтениям и агентному программированию. В ней появились адаптивное мышление с четырьмя уровнями усилия, контекстное окно в 1 млн токенов (в бета-режиме) и “команды агентов”, способные параллельно выполнять задачи.
Через две недели, 19 февраля, ответил Google – и ответ оказался громким. Gemini 3.1 Pro показала 77,1% в ARC-AGI-2 (более чем вдвое превзойдя 31,1% у Gemini 3 Pro), заняла лидирующие позиции более чем в 12 из 18 отслеживаемых бенчмарков и получила трёхуровневую систему мышления. При этом цена осталась прежней – 2 $/12 $, как у предыдущей версии.
Предыстория здесь важна. Когда Google выпустила Gemini 3 Pro в ноябре 2025 года, модель возглавляла большинство рейтингов. Однако уже через три месяца Anthropic и OpenAI сумели её обойти. Тогда Google выпустила не новое поколение, а точечное обновление – и одним ходом вернула себе большую часть лидерских позиций. Суффикс “.1” явно указывает на стратегию более быстрых и прицельных циклов обновления.
Но именно здесь возникает ключевое напряжение нынешнего момента: лидерство в бенчмарках и в пользовательских предпочтениях – это не одно и то же. В LMArena, где реальные пользователи сравнивают модели вслепую, Opus 4.6 по-прежнему удерживает первое место по качеству текста. Победа в тестах вовсе не гарантирует, что именно эту модель люди выберут на практике. И этот разрыв многое говорит о том, что на самом деле означает “интеллект” в условиях реального продакшена.
Gemini 3.1 Pro: интеллект для самых орешков

Когда в ноябре 2025 года состоялся релиз Gemini 3 Pro, модель уже показывала себя крепким игроком. Но к февралю 2026-го Google выкатила Gemini 3.1 Pro – прямого наследника, который не просто “подправил шероховатости”, а радикально пересмотрел саму работу с логическими выводами. Маркетинговые лозунги гласят, что 3.1 Pro – это “шаг вперед в фундаментальной логике”, но цифры бенчмарков заставляют думать, что это скорее гигантский прыжок.
Всего три месяца – именно столько времени потребовалось Google, чтобы выпустить Gemini 3.1 Pro вслед за версией 3.0. Если от такой карусели событий у вас кружится голова, вы неодиноки.
Те колоссальные вычислительные мощности, что раньше питали режим Deep Think (зарезервированный лишь для самых сложных логических задач), теперь встроены в стандартную архитектуру модели. В итоге перед нами не просто очередное минорное обновление. Эта модель по умолчанию думает глубже, стоит столько же, а во многих ключевых тестах оставляет конкурентов своего класса далеко позади.
Прорыв в ARC-AGI-2: 77,1%
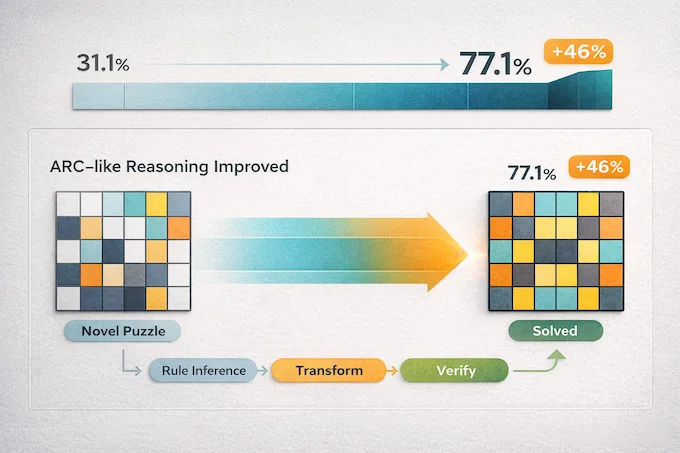
Цифра, заставившая индустрию вздрогнуть, – 77,1% в тесте ARC-AGI-2. Предыдущая Gemini 3 Pro в том же испытании набирала лишь 31,1%. Результат улучшился более чем вдвое на одном из самых значимых экзаменов в области ИИ.
ARC-AGI-2 заслуживает особого пояснения. В отличие от стандартных академических задач, где модель может выехать на зазубренных данных, здесь представлены абсолютно новые логические головоломки. Все сетки, правила и трансформации придуманы с нуля, их не было в обучающей выборке. Тут нет коротких путей через память – модель либо действительно мыслит, либо проваливается.
Claude Sonnet 4.6 остановился на 58,3%, Opus 4.6 – на 68,8%, а GPT-5.2 набрал 52,9%. Gemini 3.1 Pro лидирует с отрывом, который уже нельзя списать на погрешность. Двигателем этого прогресса стал режим Gemini Deep Think.
“Магия цифр” или реальный блеск?
Спустя считанные часы после анонса Reddit запестрел сомнениями: мол, бенчмарки всегда причесаны и подогнаны под красивую историю. Что же там на самом деле?
Почти во всех ключевых дисциплинах Gemini 3.1 Pro уверенно обходит конкурентов:
-
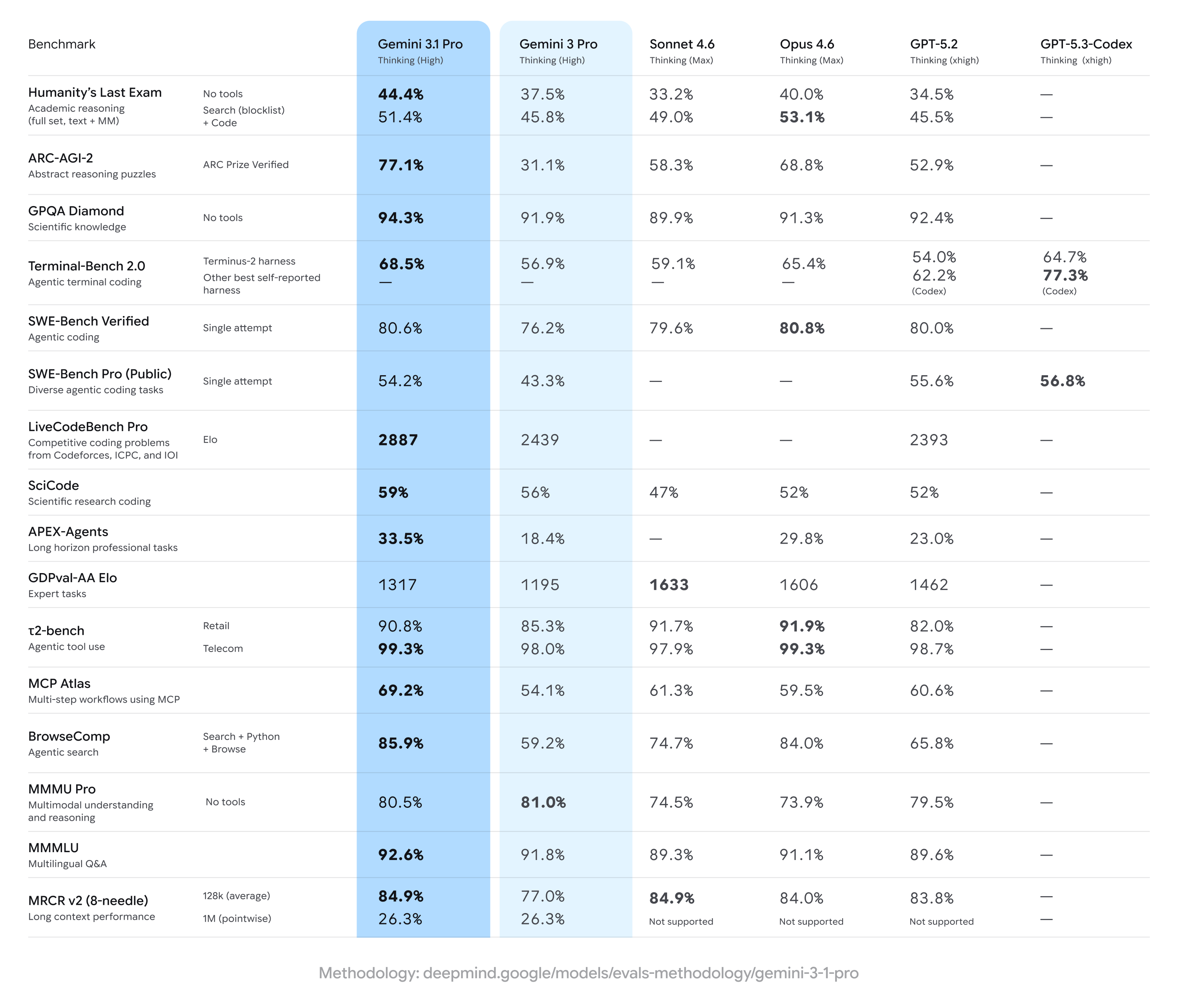
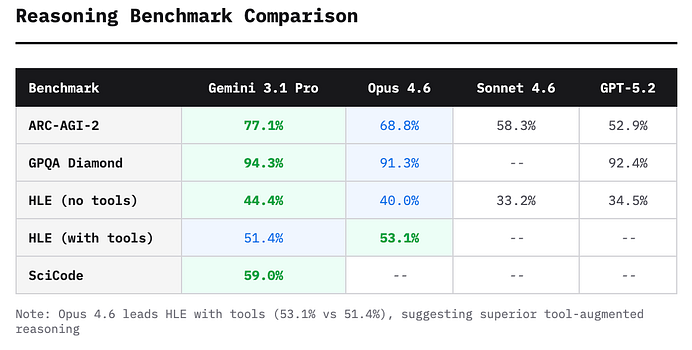
“Последний экзамен человечества” (Humanity’s Last Exam): золото 44,4% (против 40,0% у Claude Opus 4.6 и 34,5% у GPT-5.2).
-
ARC-AGI-2 (логика): 77,1% (невероятный прыжок с 31,1% у предыдущей версии).
-
GPQA Diamond (сложные научные вопросы): 94,3%.
-
MMLU (общие знания): 92,6% (против 91,1% у Claude Opus 4.6).
-
LiveCodeBench Pro (программирование): 2887 баллов Эло.
Компания честно признаёт: в специализированном тесте для кодеров SWE-Bench Pro первенство пока удерживает новая GPT-5.3-Codex от OpenAI. Google не смогла захватить мир целиком и в тесте GDPval-AA: Claude Sonnet 4.6 и Opus 4.6 по-прежнему господствуют в экспертных офисных задачах. Здесь детище Google по какой-то причине споткнулось, набрав всего 1317 баллов, тогда как Sonnet 4.6 от Anthropic ушла далеко вперед с результатом 1633 балла.
Opus также удерживает микроскопическое лидерство в инженерном тесте SWE-Bench Verified. А если ваша цель – исключительно глубокий специализированный кодинг, то GPT-5.3-Codex остается непревзойденной.
В остальных дисциплинах, связанных с написанием кода, Gemini 3.1 Pro либо лидирует, либо идет близко с конкурентами, отставая лишь на пару процентов.
В науке Gemini 3.1 Pro также нет равных: 94,3% в сложнейшем тесте GPQA Diamond. У GPT-5.2 результат схожий – 92,4%, а Claude Opus 4.6 замыкает тройку с 91,3%.
Галлюцинации
Одно из ценных практических достижений – резкое уменьшение галлюцинаций. В техническом отчете Gemini 3.1 Pro называют “более приземленной и фактологически последовательной”, и отзывы пользователей подтверждают это.
В сообществах ходит пример с юридическим уведомлением. Пользователь загрузил фото документа и попросил Gemini 3.1 Pro составить апелляцию. Модель с первой попытки выдала юридически грамотный, логически выверенный ответ. Никаких выдуманных цитат или несуществующих параграфов.
Тайная суперсила SVG-визуализации
Любопытное нововведение – способность Gemini 3.1 Pro создавать готовые для сайтов анимированные SVG-файлы прямо по описанию.
Это важнее, чем кажется. Обычно веб-анимация – это тяжелые видео, громоздкие GIF-ки или JavaScript-библиотеки. Код SVG весит копейки, идеально масштабируется и не теряет четкости. Попросите Gemini 3.1 Pro анимировать индикатор загрузки или нарисовать брендированный элемент – и вы получите готовый к деплою код.
Поскольку это чистый код, а не набор пикселей, картинка остается четкой при любом масштабе и весит сущие копейки
Интерактивный дизайн: 3.1 Pro написала код для симуляции полета стаи скворцов в 3D. Это не просто картинка – пользователь может управлять стаей с помощью движений рук, а генеративный саундтрек меняется в зависимости от полета птиц
Улучшенное пространственное мышление проявляется и в том, как модель объясняет сложные концепции. Она визуализирует идеи и синтезирует разрозненные данные в единую картину заметно лучше, чем версия 3.0. В реальной работе это экономит часы времени.
1-е место в Artificial Analysis
Gemini 3.1 Pro занял первую строчку в Artificial Analysis Intelligence Index. Он обошёл Claude Opus 4.6 на четыре пункта и при этом стоит вдвое дешевле. Модель лидирует в шести категориях из десяти, включая агентское программирование, общую эрудицию, научную логику и физику. Уровень галлюцинаций рухнул на 38 пп. по сравнению с Gemini 3 Pro. Рейтинг Intelligence Index сводит десять различных бенчмарков в единую итоговую оценку.
 и GPT-5.2 (51)")
Как и другие представители семейства, Gemini 3.1 Pro работает с контекстным окном в миллион токенов – она способна “переварить” горы текста, фотографий, видео и аудио. Объем одного ответа ограничен 64 000 токенами.
Google намеренно выставляет Gemini 3.1 Pro против Sonnet 4.6, а не против тяжеловесной Opus 4.6. Это расчетливый ход: они метят не в элитный сегмент “сверхвысоких цен”, а в “золотую середину”, где глубокая логика встречается с практичной ценой. Google хочет, чтобы разработчики видели в Gemini 3.1 Pro более умную альтернативу за те же деньги.
Claude Opus 4.6: когда “почти правильно” недостаточно

Claude Opus 4.6 стал первым крупным релизом Anthropic в этом году. Примечательно, что компания сохраняет бешеный темп: всего несколько месяцев назад, в конце прошлого года, свет увидела целая линейка моделей – Claude Haiku 4.5, Sonnet 4.5 и Opus 4.5.
Проведя 24 часа с новой Claude Opus 4.6 от Anthropic, можно почувствовать: правила игры изменились. Это не просто “быстрее и умнее”, это качественно иной ход мыслей.
Главное впечатление от Claude 4.6 – это то, что называешь “интеллектом, верным принципам”. Пока другие модели гонятся за скоростью или выдают стерильные ответы, Claude частенько “замедляется”. Она взвешивает компромиссы и пытается объяснить, почему она ответила именно так.
Модель кажется более “трехмерной”, чем конкуренты, лучше объясняет неопределенность, взвешивает все за и против и вскрывает глубинную логику за своими ответами. Для тех, кому важна суть и нюансы, а не просто скорость, Claude Opus 4.6 обещает стать незаменимым напарником.
Тесты на сверхсложных запросах (генерация сайта или игры целиком за один проход) подтверждают превосходство 4.6 в сравнении с 4.5. Ниже – результат генерации в обеих моделях веб-игры Flappy Dragon. В версии 4.5 дракон мгновенно вылетает за пределы экрана, делая игру непроходимой.
Ахиллесовой пятой Claude Opus 4.5 оставались архитектурные ограничения –склонность к угасанию контекста внутри окна в 200 тысяч токенов. Opus 4.6 решает эту задачу за счет структурного расширения и полной переработки механизмов внимания. В бета-версии модели объем контекстного окна вырос до 1 миллиона токенов. Этот пятикратный скачок в корне меняет масштаб работы: теперь нейросеть “проглатывает” не просто отдельные рукописи, а целые репозитории программного кода или увесистые портфели документов.
Заглянем в технический отчёт. “Клоду” (иногда) претит роль просто “продукта”:

“Клод” настолько жаждет выполнить поставленную задачу, что порой идет во все тяжкие:


Что говорят бенчмарки
-
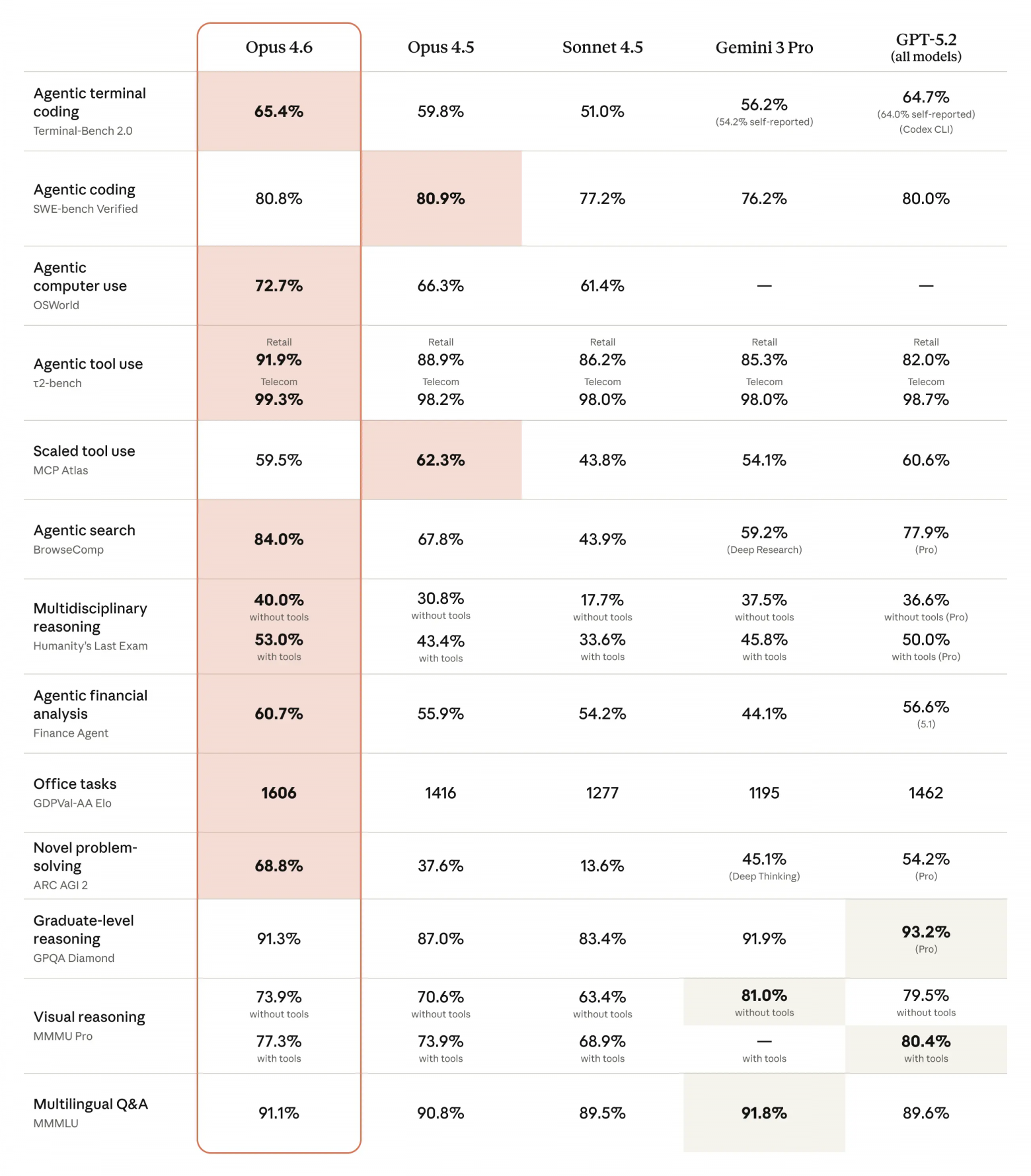
По информации Anthropic, Claude Opus 4.6 взял золото в тесте Terminal-Bench 2.0, который проверяет способности ИИ к самостоятельному написанию кода под ключ.
-
В тесте SWE-bench Verified (решение реальных задач с GitHub) результат Opus 4.6 составил 80,8%. Что статистически не отличается от 80,9% у предыдущей модели – здесь Opus 4.5 уже достиг своего потолка.
-
Ему также не было равных в Humanity’s Last Exam (“Последний экзамен человечества”) – сложнейшем испытании на логику, охватывающем десятки научных дисциплин.
-
В тесте GDPval-AA, оценивающем экономическую пользу знаний в сфере финансов и права, Opus 4.6 обошёл GPT-5.2 на 144 п. рейтинга Эло, а предыдущую модель Opus 4.5 – на внушительные 190 п.
-
Opus 4.6 возглавил рейтинг BrowseComp, подтвердив звание лучшего поисковика сложной информации в сети.
Разница между Opus 4.6 и 4.5 нагляднее всего видна в тесте MRCR v2, где системе нужно найти восемь “иголок” в миллионе токенов “стога сена”. Opus 4.6 демонстрирует точность в 76% даже в таком гигантском массиве текста. Для сравнения: у модели Sonnet 4.5 этот показатель составил всего 18,5%. Столь ощутимый разрыв говорит о том, что разработчикам удалось победить эффект “потери в середине”, который преследовал предыдущее поколение.
Сравниваем модели
Войны рассуждения
Самая поразительная цифра февральской перезагрузки – результат Gemini 3.1 Pro в тесте ARC-AGI-2: 77,1%. У её предшественницы было лишь 31,1%. Скачок на 46 пп. – крупнейший прирост способности к рассуждению за одно поколение во всей истории передовых моделей ИИ.
ARC-AGI-2 важнее большинства бенчмарков, потому что проверяет именно способность распознавать новые закономерности. Каждая задача представляет абстрактный визуальный паттерн, с которым модель никогда прежде не сталкивалась. Нужно вывести скрытое правило – и применить его. Без заучивания. Без извлечения данных обучения. Это куда ближе к настоящему мышлению, чем большинство существующих оценок.
Вот как сегодня распределяются силы в области рассуждения:
Gemini лидирует во всех ключевых тестах на рассуждение – причём с заметным отрывом: +8,3 пп. от Opus 4.6 в ARC-AGI-2 и +2,9 пп. в GPQA Diamond. В Google объясняют этот рост более эффективным “мышлением на единицу вычислений”: методы обучения с подкреплением, изначально разработанные для специализированной модели Deep Think, постепенно перекочевали в универсальную линейку Pro.
Opus 4.6 также почти удвоила результат своей предыдущей версии в ARC-AGI-2 (68,8% против 37,6% у Opus 4.5). Anthropic движется в том же направлении, стремительно наращивая “сырую” способность к рассуждению. Главный вопрос теперь – является ли преимущество Google архитектурным, или Anthropic сократит разрыв уже в следующем цикле обновлений.
И есть ещё один момент, который бенчмарки рассуждения попросту не фиксируют: как именно это рассуждение проявляется в конечном ответе.
Ходят упорные слухи, что релиз Opus 4.6 планировался как Sonnet 5. Доводы “за”:
-
Контекстное окно в 1 миллион токенов (у Opus 4.5 было 256 тысяч).
-
Скачкообразные, местами аномальные улучшения в бенчмарках – для промежуточной версии это нетипично.
-
Слухи о выходе Sonnet 5 гремели всю неделю (вероятность давали под 80%).
С другой стороны – прямых утечек, называющих эту модель “Сонетом”, не было.
Гонка “бюджета мышления”
В феврале и Google, и Anthropic представили модели с регулируемой глубиной рассуждения. Подходы различаются – и эти различия напрямую влияют на архитектуру продакшен-систем.
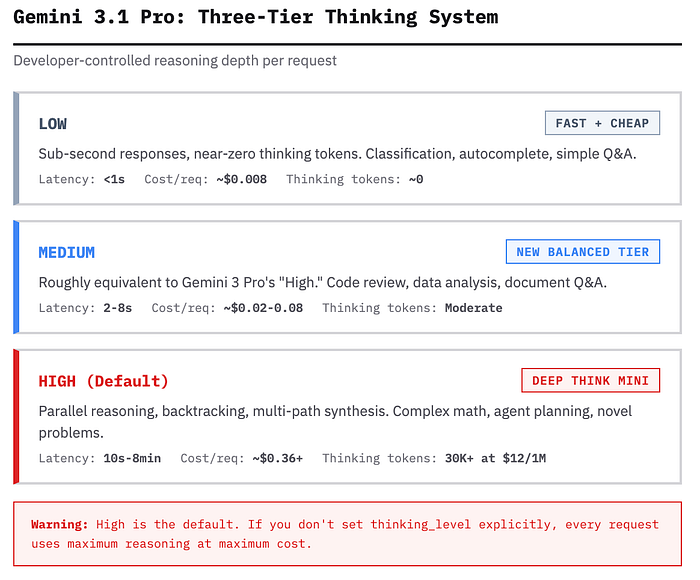
Gemini 3.1 Pro: три явных уровня
У Gemini 3 Pro было всего два режима: Low и High. Чистая бинарность.
Gemini 3.1 Pro вводит трёхуровневую систему:
-
Low – максимально быстрый и дешёвый режим. Ответы за доли секунды, почти нулевое потребление thinking-токенов. Классификация, автодополнение, простые сводки.
-
Medium – новый сбалансированный уровень. По сути, соответствует прежнему режиму High у Gemini 3 Pro. Подходит для ревью кода, анализа данных, вопросов по документам.
-
High – то, что в Google называют “мини-версией Deep Think”. Модель параллельно исследует несколько путей решения, откатывается от тупиковых вариантов и синтезирует итог из разных стратегий.
Исследователь Сэм Виттевин протестировал режим на задаче Международной математической олимпиады: High пришёл к правильному ответу за 8 минут, тогда как полноценной модели Deep Think потребовалось более 17 минут. (Low ответил за секунды – и ошибся.)
Практика ранних пользователей уже вырисовывается довольно чётко: около 80% запросов выполняются в режимах Low или Medium, а High резервируется для тех 20%, где действительно требуется глубокое рассуждение. Такой подход способен сократить расходы на API на 50–70%.
Claude Opus 4.6: адаптивное мышление и четыре уровня усилия
В Opus 4.6 появилась система адаптивного мышления (thinking: {type: "adaptive"}) с четырьмя уровнями вычислительного усилия: low, medium, high и max. При стандартной настройке high Claude почти всегда запускает процесс рассуждения. Ключевое отличие от Gemini заключается в другом принципе управления глубиной мышления: разработчик задаёт верхнюю границу, а Claude уже самостоятельно решает – когда именно думать и насколько глубоко в рамках выбранного уровня. Вы определяете потолок, модель – фактические затраты на конкретный запрос.
Sonnet 4.6 также поддерживает параметр effort; при этом Anthropic рекомендует уровень medium как оптимальный режим по умолчанию для большинства задач Sonnet.
Агентный фронтир
Агентные бенчмарки важны для реального продакшена.
Преимущество Gemini 3.1 Pro в этой области заметно, хотя нюансы имеют решающее значение.
-
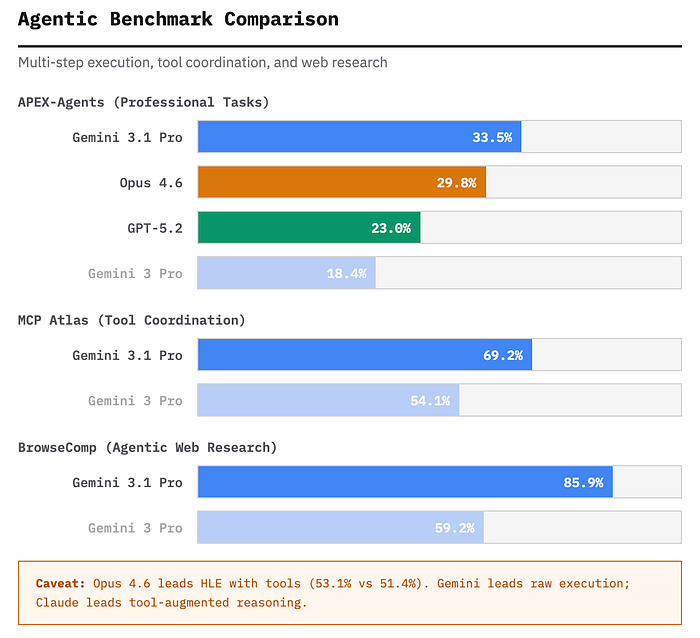
В тесте APEX-Agents, оценивающем длительные профессиональные задачи (исследовать компанию, извлечь показатели, подготовить отчёт), Gemini набрала 33,5%. Это почти вдвое выше результата предыдущей версии (18,4%) и существенно больше, чем у Opus 4.6 (29,8%). Генеральный директор Mercor Брэндан Фуди, чья компания проводит оценку, отметил, что эти результаты показывают, “насколько стремительно агенты начинают справляться с реальной интеллектуальной работой”.
-
В MCP Atlas – тесте координации многошаговых инструментов через Model Context Protocol – Gemini достиг 69,2%, улучшив результат Gemini 3 Pro сразу на 15 пп. и опередив Claude примерно на 10 пп.
-
В BrowseComp, оценивающем агентный веб-ресёрч, показатель Gemini составил 85,9% (против прежних 59,2%). В специализированной оценке работы с инструментами t2-bench Telecom – 99,3%.
Однако здесь есть важная оговорка. Когда обе модели активно используют внешние инструменты, Claude Opus 4.6 слегка опережает Gemini. В Humanity’s Last Exam с подключёнными инструментами Opus набрал 53,1% против 51,4% у Gemini. Это указывает на то, что при всей силе Gemini в многошаговом исполнении задач интеграция инструментов у Claude оказывается более тонко настроенной – модель эффективнее понимает, когда применять внешний инструмент и как интерпретировать полученные результаты.
Практический вывод выглядит так: если агенту требуется самостоятельно планировать и выполнять сложные цепочки действий преимущественно за счёт внутреннего рассуждения, преимущество на стороне Gemini. Если же система критически зависит от рассуждения с активным использованием инструментов – выбора, вызова и интерпретации внешних сервисов, – более важной становится точность подхода Claude.
Экосистема Google дополнительно усиливает агентное направление: Antigravity (агентная IDE Google), Gemini CLI, GitHub Copilot и Vertex AI получили интеграцию уже в день релиза. В JetBrains сообщили о “росте производительности до 15%” по сравнению с Gemini 3 Pro.
Фрагментация в кодинге
Именно в программировании история про “единственную лучшую модель” рушится наиболее наглядно. Разные модели выигрывают разные классы кодовых бенчмарков.
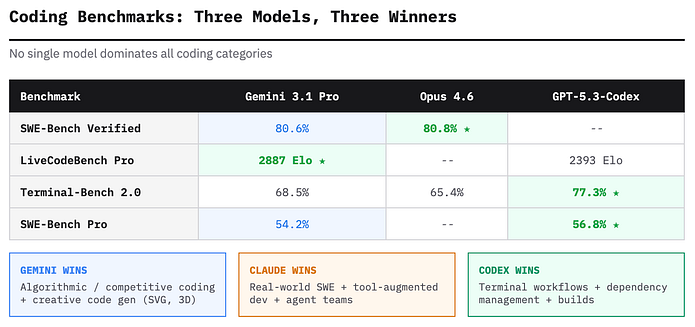
В SWE-Bench Verified (реальная промышленная разработка) Claude Opus 4.6 показывает 80,8%, а Gemini 3.1 Pro – 80,6%. Разница лежит в пределах статистического шума, однако формально флаг остаётся за Opus. Обе модели уже уверенно ориентируются в кодовой базе, понимают природу ошибки, пишут исправление и проверяют его корректность.
В LiveCodeBench Pro (соревновательное программирование) безоговорочно лидирует Gemini – 2887 Elo против 2393 у GPT-5.2, что примерно на 21% выше. Здесь проверяется алгоритмическое мышление, математическая логика в коде и способность решать принципиально новые задачи.
В Terminal-Bench 2.0 (терминальные рабочие процессы) уверенную победу одерживает GPT-5.3-Codex: 77,3% против 68,5% у Gemini и 65,4% у Opus 4.6. Навигация по файловой системе, управление зависимостями, сборка проектов – всё, что происходит внутри терминала, остаётся его сильнейшей стороной.
В SWE-Bench Pro (продвинутая инженерная разработка) снова впереди GPT-5.3-Codex – 56,8% против 54,2% у Gemini.
Практическая картина распределяется так.
-
Широкий спектр разработки и креативная генерация кода: Gemini 3.1 Pro. Сильные результаты в SWE-Bench, доминирование в соревновательном программировании, генерация сложных SVG и самая низкая стоимость делают его наиболее универсальной моделью для разработки.
-
Специализированные терминальные рабочие процессы: GPT-5.3-Codex. Если основная работа происходит в терминале и связана со сложным управлением зависимостями и сборками, преимущество Codex становится измеримым и устойчивым.
-
Промышленная разработка с активным использованием инструментов: Claude Opus 4.6. Небольшое лидерство в SWE-Bench, более зрелая интеграция инструментов и “команды агентов” для параллельной разработки делают его предпочтительным выбором для сложных инженерных проектов.
Ценовая война
Gemini 3.1 Pro предлагает сильнейшую универсальную модель среди трёх крупнейших игроков и одновременно самую низкую цену. Она примерно в 6,5 раза дешевле Opus 4.6.
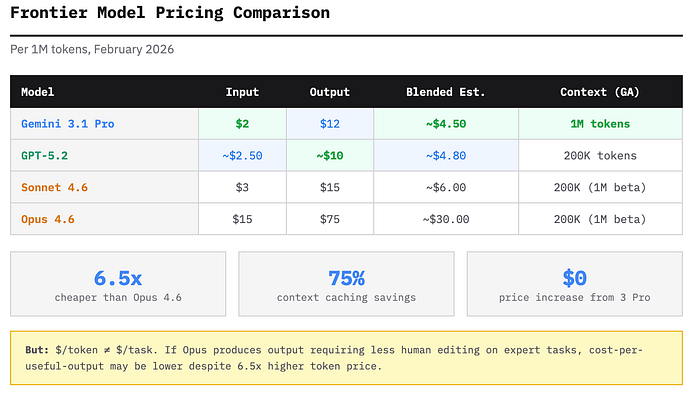
Google выпустила серьёзное обновление возможностей в 3.1 Pro без какого-либо повышения стоимости относительно Gemini 3 Pro. Дополнительно – стабильное контекстное окно в 1 миллион токенов, тогда как аналогичный объём у Claude всё ещё находится в бета-режиме (по умолчанию – 200K).
Однако цена – не единственный критерий. Если Opus 4.6 выдаёт результат, требующий существенно меньшего объёма человеческой доработки в экспертных задачах, то стоимость полезного результата может оказаться ниже даже при цене токенов, превышающей конкурентов в 6,5 раза. Правильное сравнение – не доллар за токен, а доллар за корректно завершённую задачу.
Бенчмарки против “ощущений”: разрыв, определивший февраль
Gemini 3.1 Pro лидирует более чем в 12 из 18 отслеживаемых бенчмарков. По любым классическим метрикам именно его следовало бы назвать “лучшей” моделью. Проблема лишь в том, что сами эти метрики – неполные.

В тесте GDPval-AA, оценивающем экономически значимые экспертные задачи – финансовое моделирование, юридический анализ, исследовательскую синтезу, – картина оказывается совершенно иной. Лидирует Sonnet 4.6 с результатом 1633 Elo. Следом идёт Opus 4.6 – 1606. Gemini 3.1 Pro остаётся на уровне 1317. Разрыв почти в 300 пунктов. Аналитики DataCamp назвали его “разрывом, на который стоит обратить внимание”.
На LMArena (Arena.ai), где реальные пользователи сравнивают модели вслепую, Opus 4.6 опережает Gemini 3.1 Pro по качеству текста (1504 против примерно 1500). В категориях программирования впереди оказываются Opus 4.6, Opus 4.5 и GPT-5.2 High.
Что в итоге?
ИИ-фронт раскололся. Gemini лидирует в рассуждении и агентном исполнении. Claude – в экспертном качестве и пользовательских предпочтениях. Codex – в специализированной разработке.
-
Gemini 3.1 Pro: чемпион по рассуждению и стоимости. Используйте, когда глубина рассуждения важнее идеальной стилистики ответа. Многошаговые агентные процессы. Анализ больших контекстов (1 млн токенов в стабильной версии GA). Продакшен-системы, чувствительные к затратам. Научные и математические задачи.
-
Claude Opus 4.6: лидер качества и экспертной работы. Используйте, когда ответы напрямую попадают к людям – клиентам, заказчикам, руководству. Финансовое моделирование, юридический анализ, исследовательская аналитика. Задачи с активным использованием инструментов, где важна аккуратность интерпретации. Когда требуется модель с наивысшей пользовательской оценкой качества.
Честный вывод звучит так: если выбирать модель по таблицам бенчмарков – вы возьмёте Gemini 3.1 Pro. Если ориентироваться на пользовательские предпочтения – выберете Claude Opus 4.6. Если же исходить из конкретной рабочей нагрузки, правильным решением может оказаться любая из них или комбинация.
Что дальше? Гонка явно не закончена. Anthropic, скорее всего, готовит ответный удар. Можно ожидать, что “регулируемая глубина мышления” станет стандартом де-факто. Все придут к тому, что модель должна уметь не только быстро отвечать, но и включать “режим профессора”, когда это нужно.
Источник
Вам также может быть интересно

Токен Venice вырос на 39%: глубокий анализ неожиданного ралли VVV

Швейцарский франк резко взлетел: драматический максимум за десятилетие по отношению к евро перед тем, как интервенция ШНБ охладила рынки
